
[ad_1]
I am not a gymnast. Place me in a number of parallel bars and I will probably hurt myself. So does that mean that the parallel bars are not a good test of my sporting skills? You could be characterized by certain tasks, but you could struggle with others. Similarly, the assessment of the functions of large language models (LLMS) in real coding scenarios requires a nuanced approach. Benchmarks like Sweee-Bench come into play here, but how well do you really reflect the practical benefit of a AI coding assistant?
What is SWE-bench?
 SWE-Bench, Short for Software Engineering Benchmark, is a framework that evaluates LLMS on your ability to do real software engineering tasks. It consists of 2,294 problems related to Github problems and their corresponding pull inquiries in 12 popular Python repositories. These tasks challenge models to edit code bases and often requires coordination over several functions, classes or files, interaction with execution environments and complex argument that goes beyond simple code generation. SWE-Bench aims to measure how well a AI can understand and solve software problems in a way that reflects the work of human developers.
SWE-Bench, Short for Software Engineering Benchmark, is a framework that evaluates LLMS on your ability to do real software engineering tasks. It consists of 2,294 problems related to Github problems and their corresponding pull inquiries in 12 popular Python repositories. These tasks challenge models to edit code bases and often requires coordination over several functions, classes or files, interaction with execution environments and complex argument that goes beyond simple code generation. SWE-Bench aims to measure how well a AI can understand and solve software problems in a way that reflects the work of human developers.
Why is SWE-Bench important?
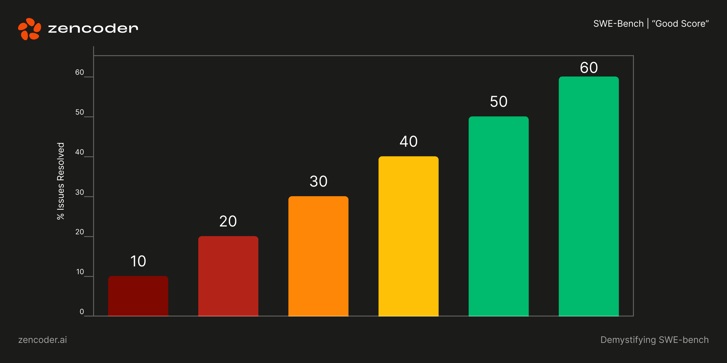
The SWE-bench values offer a quantitative measure of the ability of an LLM to cope with the coding challenges in the real world. A higher score shows a greater capacity to generate a useful, error -free code that integrates well into existing projects. This is crucial because it offers a standardized way to compare different AI coding assistants. For example:
- A score below 30% suggests that the tool has to deal with complex scenarios and often do not create helpful or incorrect code.
- A score over 50% Displays strong skills for problem solving and may place the tool into the upper level of AI coding assistants.
The SWE-Bench restrictions
While SWE-Bench is a valuable tool, it is important to recognize its limits:
Data contamination: Many problems in the SWE-bench were created before the training degrees of several LLMs. This could lead to data loss in which models may have been exposed to solutions during training and possibly inflate the performance values.
Lack of real representation: SWE-Bench mainly focuses on python repositors, which may not fully represent the variety of programming languages and software engineering tasks that occur in practical development. Other languages or multi-file problems can achieve very different results.
Weak tests: Some tasks in SWE-bench may have inadequate unit tests, which leads to false positive aspects in which models seem to solve problems, but have not really addressed the underlying problems. In addition, some tools can try to “play” the system by running under unrealistic laboratory conditions, which leads to inflated reviews that do not reflect any real performance.
Benchmark specificity: The SWE-Bench reviews can sometimes reflect the strength of a model on known data records instead of generalizing to new or different coding scenarios. In practice, developers often indicate that due to syntax errors, hallucinations and a poor understanding of context, they spend considerable time to debug the code for syntax.
Zencodier: solving coding challenges in the real world
At Zenzoder, we understand that the real measure of a AI coding assistant lies in its ability to solve real problems, not only to score well with benchmarks. While SWE-Bench offers a useful starting point, we focus on managing the central challenges that the developers look for every day. We understand that SWE-Bench will never be our goal at Zencoder to “Bench-Max”. Our value can only be sent on time with the customer, the real team, which is located in the trenches. For this reason, we have geared towards the most important headache that inspired parts of a software engineer.
Repo grokking ™: deep context -related understanding
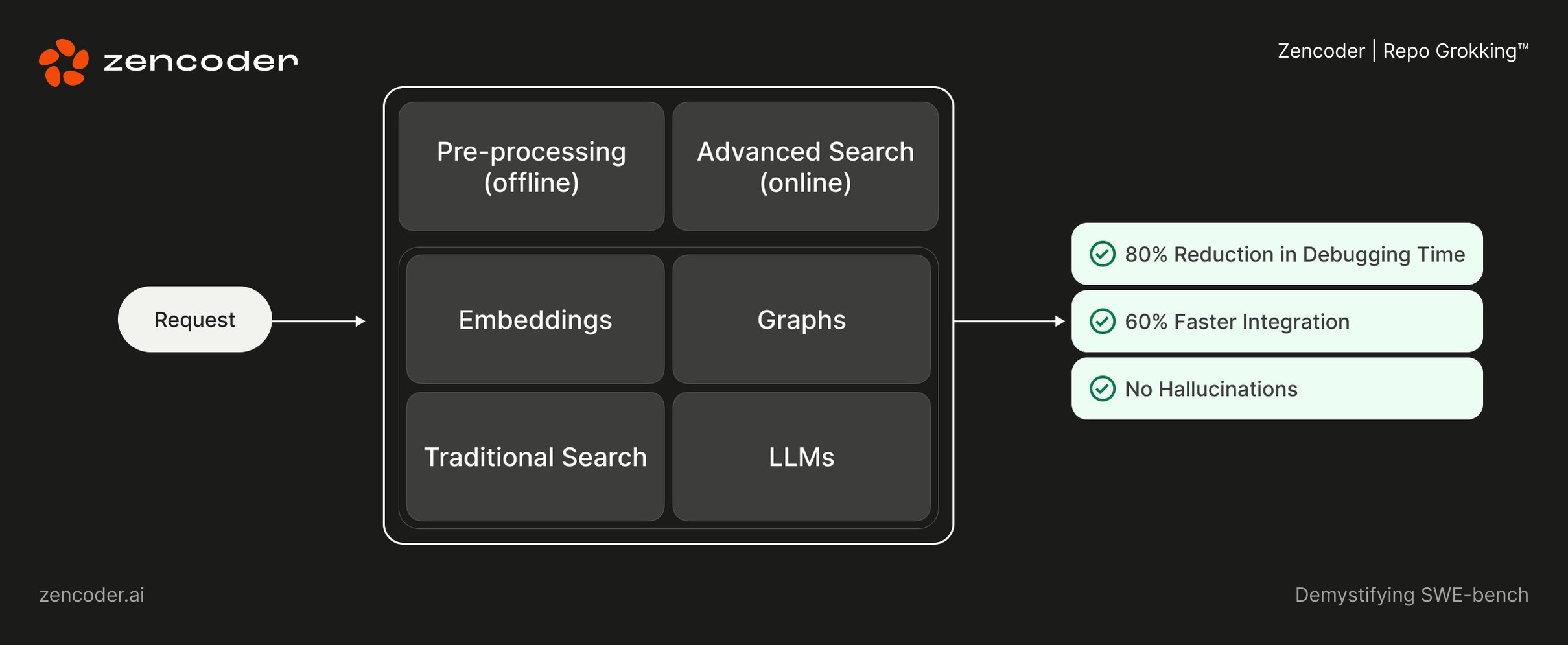
The REPO GROKKING ™ technology from Zencoder analyzes its entire code base and understanding of dependencies, libraries and architectural patterns. This deep context -related awareness enables the zenzoder:
- Reduce the debugging time: Generate an exact, context -conscious code that is tailored to your repository. Users report 80%up to a time reduction of the time.
- Faster integration: Provide solutions that seamlessly integrate into existing workflows, with users experience faster integration of up to 60%.
- Eliminate hallucinations: Make sure that suggestions are relevant and exactly by using a comprehensive understanding of your project.
Agent pipelines: continuous learning and improvement
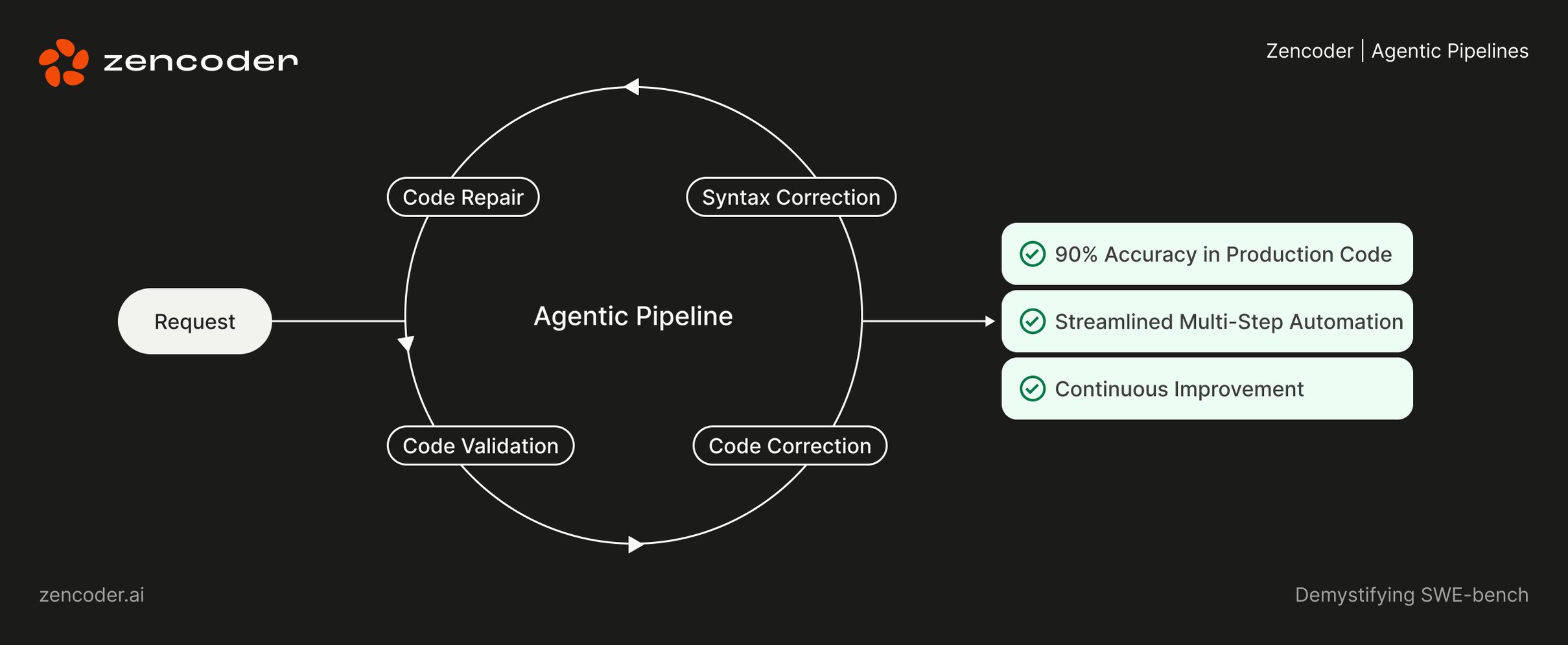
The Zenencoder agent pipelines go beyond the production of the static code. They use self -improveing mechanisms to autonomously validate, correct and refine the expenditure. This leads to:
- High accuracy: exits meet strict standards and reduce the need for manual intervention. Users report up to 90% accuracy in the production code.
- Multi-stage automation: dealing with complex tasks such as multi-file updates and advanced refactoring with ease.
- Continuous improvement: imitate the iterative argumentation process of experienced engineers and improve with every use.
Diploma
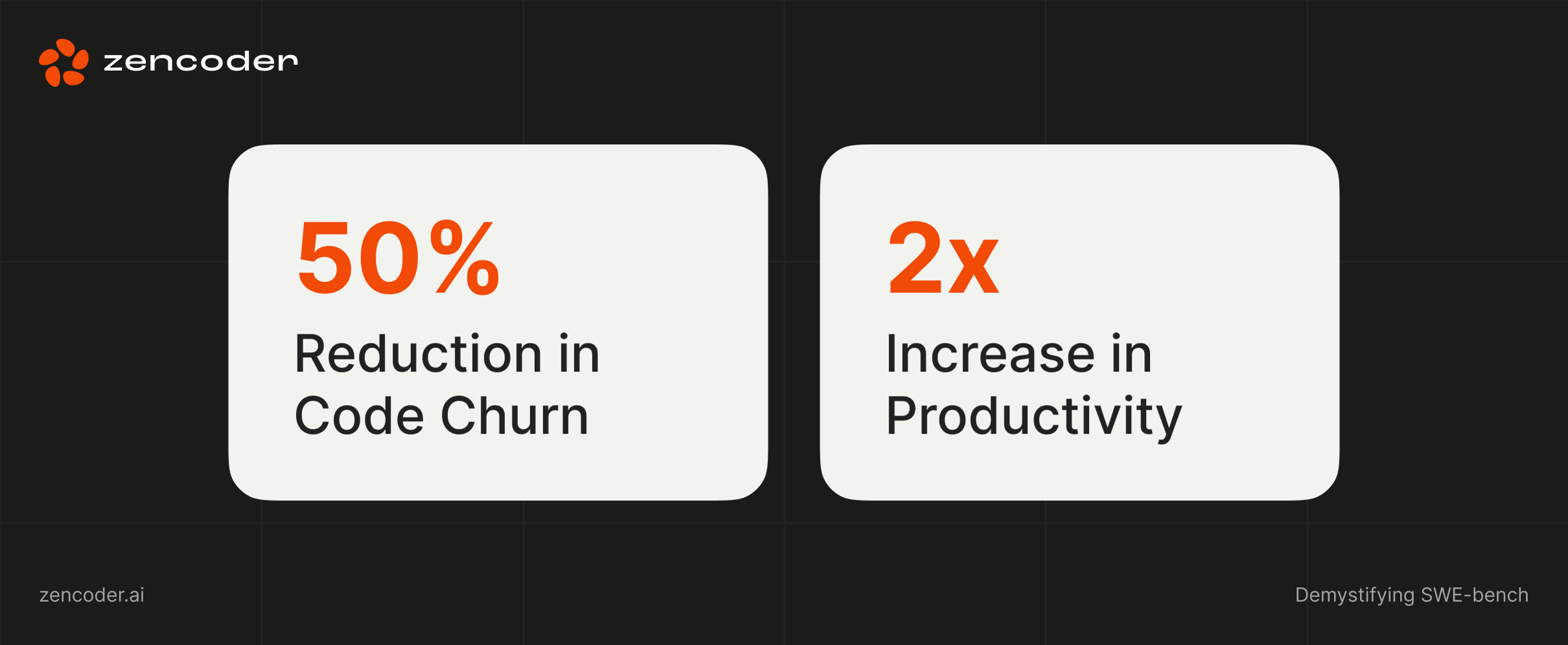
SWE-Bench is a valuable instrument for evaluating LLM-based code-completion tools and offers insights into your ability to do real software engineering tasks. However, it is crucial to understand your limits and not only rely on benchmark values. ZenCoder offers a practical solution that deals with the core challenges that developers face and use a deep context -related understanding and continuous learning to provide precise, reliable and efficient codegenization. While others are too much obliged and below average, Zenzoder proves that the AI can change the coding today. Here is what our SWE-Bench score means in practice: 50% reduction in code groans, cleaner, ready-to-production expenditure and a 2-time increase in productivity and the liberation of developers to focus on innovation. With Zenzoder, the future of coding is no longer a distant promise. It’s here.
[ad_2]

